A wide range of domestic macroeconomic data can be obtained from the Tushare platform using Tushare's built-in functions, such as money supply, reserve requirement ratio, deposit and loan rates, GDP, consumer price index and ex-factory industrial price index for multiple periods.

The ts.get_money_supply() function allows you to obtain data on our money supply for each of the last 30 years.
import tushare as ts
df = ts.get_money_supply()
df.head()
df.columns
 Return value description.
Return value description.
| Parameter | Explanation |
|---|
| month | Statistics time |
| m2 | Monetary and quasi-monetary (broad money M2) (billion yuan) |
| m2_yoy | Monetary and quasi-monetary (broad money M2) year-on-year growth (%) |
| m1 | Money (Narrow Money M1) (billions of yuan) |
| m1_yoy | Money (narrow money M1) year-on-year growth (%) |
| m0 | Cash in circulation (M0) ($bn) |
| m0_yoy | Cash in circulation (M0) year-on-year growth (%) |
| cd | Demand deposits ($bn) |
| cd_yoy | Demand deposits growth (%) |
| qm | Quasi-currency ($bn) |
| qm_yoy | Quasi-currency growth (%) |
| ftd | Time deposits ($bn) |
| ftd_yoy | Year-on-year growth in time deposits (%) |
| sd | Savings deposits ($bn) |
| sd_yoy | Savings deposits growth (%) |
| rests | Other deposits ($bn) |
| rests_yoy | Year-on-year growth in other deposits (%) |
Tushare provides corresponding interface functions for different types of interest rates in order for developers to obtain the required interest rate data. The deposit rate function get_deposit_rate() and the loan rate function get_loan_rate() can be used to obtain the deposit rate and loan rate data issued by the People's Bank of China since 1989 respectively.
import tushare as ts
df = ts. get_loan_rate()
df.head()

The Shanghai Interbank Offered Rate (Shibor) is the arithmetic average of the RMB interbank offered rates calculated and determined by a quotation group of banks with high credit ratings, using the National Interbank Offered Rate Centre in Shanghai as the technical platform to calculate, publish and name the rate.
import tushare as ts
pro = ts.pro_api('用户tushare token')
df=pro.shibor()
df.head()
 Other interest rate pro interface functions.
(1) pro.shibor_quote():Shibor quoted data
(2) pro.shibor_lpr():LPR lending base rate
(3) pro.libor():LIBOR
(4) pro.Hibor():Hong Kong Interbank Offered Rate
Other interest rate pro interface functions.
(1) pro.shibor_quote():Shibor quoted data
(2) pro.shibor_lpr():LPR lending base rate
(3) pro.libor():LIBOR
(4) pro.Hibor():Hong Kong Interbank Offered Rate
From the Tushare platform, users can access the stock trading data of all listed companies on the Shanghai Stock Exchange and Shenzhen Stock Exchange, as well as the data of various stock indices (e.g. SSE Composite Index, SZSE Component Index, GEM Index, CSI 300 Index and SMB Index, etc.) of these two markets.
The following commands can be executed in sequence to obtain historical daily ticker data for stock code 600848.
import tushare as ts
df = ts.get_hist_data('600848', ktype = 'D')
df.head()

 Return value description.
Return value description.
| Parameter | Explanation |
|---|
| date | Date |
| open | Opening price |
| high | Highest price |
| close | Closing price |
| low | Lowest price |
| volume | volume |
| price_change | price change |
| p_change | price_change |
| ma5 | 5-day average |
| ma10 | 10 Day Average |
| ma20 | 20 Day Average |
| v_ma5 | 5-day average volume |
| v_ma10 | 10 Day Average |
| v_ma20 | 20 Day Average |
| turnover | turnover |
The Tushare package provides a number of pro interface functions to return historical stock data. Registered users of the platform can use the pro interface functions to obtain stock quotes, but most of the pro interface functions require users to have a certain number of points before they can be called.
The operation of the pro interface function to obtain daily stock quotes is as follows.
import tushare as ts
pro = ts.pro_api()
df = pro.daily(ts_code = '600008.SH', start_date = '20000501', end_date = '20190808')
df.head()
 There are some structural differences between the quotation data obtained with the pro interface function pro.daily() and the quotation data obtained with the get_hist_data() function. The return data from the pro.daily() function uses the default index, with the date of the transaction as a field (column) data item, whereas the return data from the get_hist_data() function uses the date of the transaction as an index.
Given that the structure of the data returned by the different interface functions differs to a greater or lesser extent, it is important to design programs that process this data in such a way that the appropriate processing method is chosen based on the structure of the data returned, or that the data items returned are modified as necessary to meet the formatting requirements of other data processing statements.
There are some structural differences between the quotation data obtained with the pro interface function pro.daily() and the quotation data obtained with the get_hist_data() function. The return data from the pro.daily() function uses the default index, with the date of the transaction as a field (column) data item, whereas the return data from the get_hist_data() function uses the date of the transaction as an index.
Given that the structure of the data returned by the different interface functions differs to a greater or lesser extent, it is important to design programs that process this data in such a way that the appropriate processing method is chosen based on the structure of the data returned, or that the data items returned are modified as necessary to meet the formatting requirements of other data processing statements.
 Tushare also provides real-time data on stock trading quotes, i.e. data on the prices of stocks that are being traded on that day. For example, the real time stock trading data obtained through the get_realtime_quotes() function can include information such as the list of quotes and transaction prices of the stock at the current moment, the five buy quotes and five sell prices and other data items, with a total of more than 30 items of information. The operation process is as follows.
Tushare also provides real-time data on stock trading quotes, i.e. data on the prices of stocks that are being traded on that day. For example, the real time stock trading data obtained through the get_realtime_quotes() function can include information such as the list of quotes and transaction prices of the stock at the current moment, the five buy quotes and five sell prices and other data items, with a total of more than 30 items of information. The operation process is as follows.
import tushare as ts
df = ts.get_realtime_quotes('300274')
df[['code','name','price','bid','ask','volume','amount','time']]
 Partial return value description.
Partial return value description.
| Parameter | Explanation |
|---|
| code | Stock code |
| name | Name of the stock |
| price | Current price |
| high | Today's high price |
| low | Today's low price |
| bid | The bid price, i.e. "buy one" offer |
| ask | bid to sell, i.e. "sell one" offer |
| volume | volume maybe you need do volume/100 amount, amount traded ($ CNY) |
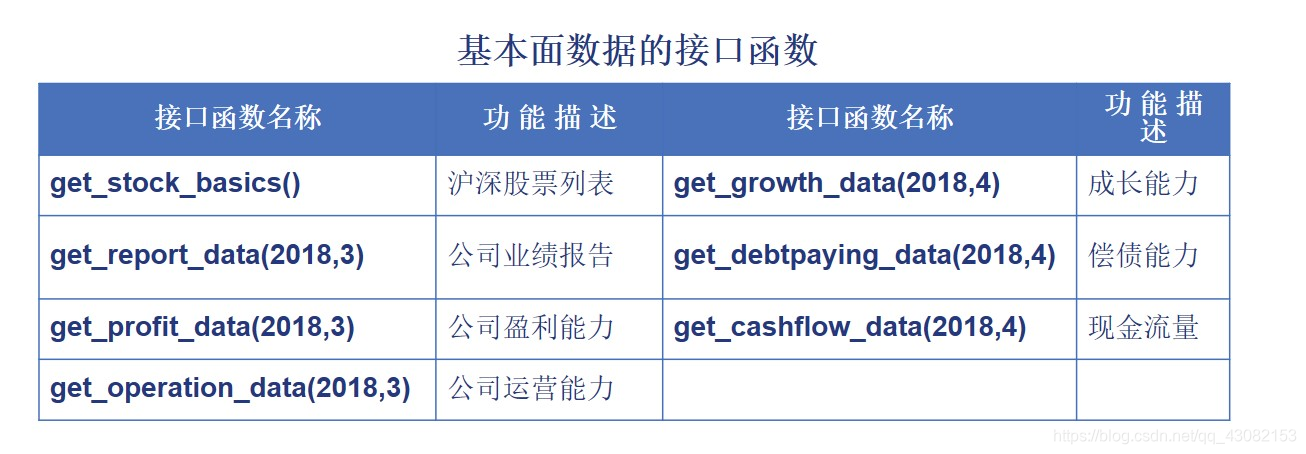
The Tushare platform provides fundamental data on listed companies, including financial position, profitability, market share, management structure, talent composition and more. In addition to stock price data, financial analysts often need fundamental data on listed companies to understand the value of a company's investment.
Tushare provides the interface functions for listed companies' fundamental data as shown in the table.
A stock index is a composite price value of stocks compiled by a stock exchange or financial services institution that reflects the price movements of a particular group (class) of stocks.
Stock exchanges and some financial services institutions have compiled and publicly released dozens of stock price indices, and stock investors are accustomed to using stock indices as an observational indicator of stock market price movements.
The pro.index_basic () function can be used to obtain the various stock indices published by the SSE.
import tushare as ts
pro = ts.pro_api('用户tushare token')
df = pro.index_basic(market = 'SSE')
df.head()
 The following two tables list the input and output parameters of the Tushare platform pro version interface function index_basic().
The following two tables list the input and output parameters of the Tushare platform pro version interface function index_basic().








 From the data items returned by the functions listed in the table above, the interface function returns a very rich variety of data that can be used to reflect the value of the company's investment in a number of combinations of data items. For example, the return parameters from the three types of data listed in the table above select the net interest rate, return on net assets, earnings per share growth rate, net profit growth rate, earnings per share growth rate, the ratio of net operating cash flow to net profit and cash flow ratio as key evaluation indicators, and the comprehensive use of the value of these seven indicators to reflect the quality of the company's fundamentals. Generally, the higher the value of these indicators, the higher the fundamental quality of the company and the greater the investment value of the company's shares. The following program demonstrates a method of using financial indicator data to screen for quality company stocks.
From the data items returned by the functions listed in the table above, the interface function returns a very rich variety of data that can be used to reflect the value of the company's investment in a number of combinations of data items. For example, the return parameters from the three types of data listed in the table above select the net interest rate, return on net assets, earnings per share growth rate, net profit growth rate, earnings per share growth rate, the ratio of net operating cash flow to net profit and cash flow ratio as key evaluation indicators, and the comprehensive use of the value of these seven indicators to reflect the quality of the company's fundamentals. Generally, the higher the value of these indicators, the higher the fundamental quality of the company and the greater the investment value of the company's shares. The following program demonstrates a method of using financial indicator data to screen for quality company stocks.  如果在If you have saved the financial data file before running the program, you can read the financial data directly from the local data file, thus avoiding the need to download the same data every time you run the program.
如果在If you have saved the financial data file before running the program, you can read the financial data directly from the local data file, thus avoiding the need to download the same data every time you run the program. The disclosure time for financial reports of A-share listed companies in China is stipulated as follows: the first quarterly report is disclosed by 30 April, the half-yearly report by 31 August, the third quarterly report by 30 October, and the annual report is disclosed by 30 April of the following year. The program uses the date function of the datatime package to determine the available financial report data.
The disclosure time for financial reports of A-share listed companies in China is stipulated as follows: the first quarterly report is disclosed by 30 April, the half-yearly report by 31 August, the third quarterly report by 30 October, and the annual report is disclosed by 30 April of the following year. The program uses the date function of the datatime package to determine the available financial report data.

 The size of the dataset is 3823x22 and each row is the basic data for one stock. See Tushare's website for field details. See the
The size of the dataset is 3823x22 and each row is the basic data for one stock. See Tushare's website for field details. See the 


 As can be seen from the above statistics, the more economically developed and dynamic the region, the greater the number of listed companies. The reader can also perform similar statistics by industry. The timeToMarket field in the data box represents the date of listing and is an integer in the format of "20190315". We can extract the year from it to count the number of shares issued each year.
As can be seen from the above statistics, the more economically developed and dynamic the region, the greater the number of listed companies. The reader can also perform similar statistics by industry. The timeToMarket field in the data box represents the date of listing and is an integer in the format of "20190315". We can extract the year from it to count the number of shares issued each year. 
 从图中It can be seen that several highs in the year of IPO issuance correspond to several bull market times in the domestic stock market, with the number of issuances falling to a low during bear markets. The following calculates the market's average price-to-earnings ratio, pe, which is an important parameter in measuring stock market valuation.
从图中It can be seen that several highs in the year of IPO issuance correspond to several bull market times in the domestic stock market, with the number of issuances falling to a low during bear markets. The following calculates the market's average price-to-earnings ratio, pe, which is an important parameter in measuring stock market valuation.  Looking at the dataset reveals that the pe of loss-making stocks in the dataset is 0. Therefore, the removal of loss-making stocks is considered.
Looking at the dataset reveals that the pe of loss-making stocks in the dataset is 0. Therefore, the removal of loss-making stocks is considered.  The pe above is a simple arithmetic average, a weighted pe with market capitalisation as the weighting may be a more accurate reflection of market conditions. As the total market capitalisation and stock unit prices are not available in the downloaded dataset, the total market capitalisation can only be extrapolated from the available fields. It is also common in data processing to calculate new column values from the values of certain columns. Here the total market capitalisation is extrapolated on the basis of
Unit price of stock = 4esp (earnings per share) pe (price-to-earnings ratio)
Total market capitalisation = share unit price *totals total equity (RMB billion)
The earnings per share esp in the dataset is for a single quarter, so multiply the full year earnings by 4.
The pe above is a simple arithmetic average, a weighted pe with market capitalisation as the weighting may be a more accurate reflection of market conditions. As the total market capitalisation and stock unit prices are not available in the downloaded dataset, the total market capitalisation can only be extrapolated from the available fields. It is also common in data processing to calculate new column values from the values of certain columns. Here the total market capitalisation is extrapolated on the basis of
Unit price of stock = 4esp (earnings per share) pe (price-to-earnings ratio)
Total market capitalisation = share unit price *totals total equity (RMB billion)
The earnings per share esp in the dataset is for a single quarter, so multiply the full year earnings by 4. The above calculation reflects the market-weighted pe after a particular quarterly report and the result differs from the true market value. This is because stocks have different returns each quarter and therefore you cannot simply calculate the full year return on a "4*single quarter return" basis.
The above calculation reflects the market-weighted pe after a particular quarterly report and the result differs from the true market value. This is because stocks have different returns each quarter and therefore you cannot simply calculate the full year return on a "4*single quarter return" basis.
 The data returned by Tushare's built-in functions are all of the DataFrame type of Pandas, so it is easier to manipulate the data returned by these functions using the manipulation tools provided by Pandas, NumPy, Matplotlib and other packages.
The data returned by Tushare's built-in functions are all of the DataFrame type of Pandas, so it is easier to manipulate the data returned by these functions using the manipulation tools provided by Pandas, NumPy, Matplotlib and other packages. Return Value Description:
Return Value Description:
 (3) Use the command pip install tushare to install the Tushare package locally.
(3) Use the command pip install tushare to install the Tushare package locally.

 It looks like the results have been run, but the long string in front of it is really uncomfortable to watch. This, coupled with the fact that ==Process finished with exit code 1== makes me even more convinced that there is something fishy going on here.
It looks like the results have been run, but the long string in front of it is really uncomfortable to watch. This, coupled with the fact that ==Process finished with exit code 1== makes me even more convinced that there is something fishy going on here. As you can see, the headache-inducing red error message is gone, and ==Process finished with exit code 0==
The problem seems to have been solved, but we know that this is only superficial and that the problem has not been solved, but we have chosen not to display it. The cure is not the cause!
As you can see, the headache-inducing red error message is gone, and ==Process finished with exit code 0==
The problem seems to have been solved, but we know that this is only superficial and that the problem has not been solved, but we have chosen not to display it. The cure is not the cause! After removing the blank line at the end, run the program again:
After removing the blank line at the end, run the program again:
 Now that's perfect!
Comfortable =。=
Now that's perfect!
Comfortable =。= A variety of different styles of images will be produced in the tmp directory.
A variety of different styles of images will be produced in the tmp directory.