一篇关于网址、URL、IP地址、域名、DNS、域名解析的白话长文。
编写形式:QA
互联网上的所有数据都是存储在主机(服务器)上
互联网中的所有主机都拥有唯一的IP地址
互联网中任意两台主机通信都是通过IP地址来实现
了解上述内容之后,我们以两台主机最简单的通信方式——上网为例,为大家说明这个疑问是什么。
21世纪的每个人应该都熟悉网上冲浪(不知道还有没有人用这个词)的过程,我们上网的实质就是获取网址对应主机上的数据并在用户主机上进行展示(浏览器上),那么我们就该怀疑一个问题:
互联网中的任意两台主机通信是依靠IP地址进行的,而我们上网只是输入的网址,并不是IP地址,怎么就能找到对方主机并获取它的数据呢?
因此,势必存在某种机制,将网址解析成为了IP地址,再通过IP地址进行通信!这个机制也是贯穿本文所有技术知识的主线!
网址,也叫做域名,又称URL,是互联网用户用来标识主机的名字,该名字具有唯一性,层次性,字面意义可以表示主机的账号、功能、性质、所属的地区或组织,便于所有互联网用户记忆与使用!
URL,即Uniform Resource Locator,统一资源定位符,用于指明互联网主机的服务器及具体的网页位置,URL的构成策略与示例如下:


网址/域名/URL的出现解决了以下两个问题:
问题一:IP地址是互联网中所有主机的统一寻址方式,使用IP地址能够直接访问互联网上主机数据、资源,但由于IP地址只是一串数据,不具有实际意义,导致所有互联网用户记忆起来十分困难。
问题二:在Internet架构中,几乎所有的应用层软件都不是通过IP地址来访问互联网中的主机资源,而是要求用户输入具有一定意义的主机名字来访问对应主机的。
上面提到的主机名称,也就是网址/域名的命名遵循了一定规则,这个规则便是由互联网中的“名字管理机构”来制定的,即域名系统DNS。这里先介绍下网址的组成:
互联网中的某台主机域名由其所属各级域名及其自身名字共同组成(即由子域名构成),级别从左到右依增加,最右边为顶级域名,最左边为主机自己的名字,各级子域名使用“.”隔开,常见的格式如下:
www.ustc.edu.cn
主机名.机构名.网络名.顶级域名
DNS,英文全写为Domain Name System,中文意思为域名系统,是互联网中提供域名与IP地址互相映射的分布式数据库。
1.ARPANE时代,约1969-1983,用host.txt记录计算机名与其IP地址。
2.1983年,域名系统诞生,DNS由此而来。
3.1985年,Symbolics公司注册首个.com域名。
4.1993年NetworkSolution(NSI)公司独家代理.COM、.ORG、.NET三个国际顶级域名注册权。
5.1994年开始NSI向每个域名收取100美元的注册费。
6.1997年3字母域名被注光。
7.1998年Interner域名的管理权由美国政府移交给民间机构。
8.2001年7个新顶级域名在ICANN大会上诞生。
9.2013年4字母.com域名被注光。
前文已经提到DNS域名系统是互联网中的主机域名管理系统,充当“管理员”的角色!DNS在诞生之前(ARPANET时期),互联网中的每台主机都是用一个文件来纪录所有的主机名及其IP地址,这个文件就是hosts.txt (现在是hosts文件,无后缀),所有主机都必须定期从相应站点来更新该文件,用于同步互联网中主机的新增、变更、消失。
可以想象,随着互联网中的主机数量增加,hosts文件必将越来越大,在维护更新方面的难度更是激增,主机名更是频繁发生冲突,为了解决这个问题,1983年DNS域名系统问世。
DNS是一个分层的树形结构,各层由域构成,域的意义如下:
域表示一个区域、一个范围
每个域可容纳大量主机
每个主机必有自己的域,却不一定有自己的域名地址
DNS标准规定,单个域名长度一般在63个字符以内,最长不超过255个字符
DNS标准规定,域名中的字符限26个字母(不分大小写),数字,连字符“-”(不能作为子 域名首字母与末尾字母)
域所在服务器称为域名服务器,主要用于将域名映射为IP地址(详见后文)
DNS的域名树由根域,顶级域,二级域及其子域构成,其结构图与示例如下:
 下面逐一介绍各级域:
下面逐一介绍各级域:
由互联网网络信息中心(InterNIC)负责管理,用点“.”表示,无名称,是域名系统中的最高级别域,标准域名结尾应包含根域“.”,但实际使用中该根域都是省略的,所以大家常见的网址末尾并没有“.”。
顶级域(Top-Level Domains = TLD)
隶属于根域,是仅次于根域的下一级域,由国家顶级域(ccTLD)与通用顶级域(gTLD)共同组成。国家顶级域共有243个(即全球的国家与地区总数),而通用顶级域,也叫国际域名,其数量是随着因特网的发展在逐渐增加,理论会达到无穷多个。下表罗列出了常见的通用顶级域名:

正式给组织和个人注册使用的唯一名称,如亚马逊、IBM,微软的官方网址(头条不能带网址)中的字眼“amazon”“ibm”“microsoft”就是这些企业注册的二级域名。
在二级域中的组织机构可以根据需要来进一步划分子域,如销售部门用sale子域名,业务部门用business子域名等。
前文中已经提到域名的出现是为了解决用户记忆困难的问题,实际在互联网中并不能使用域名进行主机间的通信,而仍然需要使用IP地址进行数据交互,所以DNS系统在提供域名功能的同时更大的作用是能够高效的将域名解析映射到对应主机的IP地址。这就是即将为大家介绍的域名服务器的作用。
域名服务器构成了DNS中的分布式网络系统,其功能主要是为内外主机提供域名与IP地址的互相解析映射服务。域名服务器分布在互联网的各子网中,每个域名服务器负责管理连接到本子网的所有主机,并为其提供服务,服务内容为:
客户机应用程序将目标主机域名发送给其所属子网的域名服务器,域名服务器给该客户机返回对应的目标主机IP地址;若本子网中的域名服务器无法查询到目标主机域名的IP,则根据DNS的标准IP地址解析流程提供进一步的查询服务,该过程将在下文“域名解析过程”中详细介绍。
通过域名获取对应IP地址的过程叫做域名解析,参与域名解析过程最重要的单元就是域名服务器,域名服务器的体系结构如下:

是全球级别最高,最重要的域名服务器,全世界共有13台(IPv4根域名服务器,编号为A到M),1个主根服务器和9个辅根服务器在美国,欧洲2个辅根服务器,位于英国和瑞典,亚洲1个辅根服务器,位于日本。根域名服务器只纪录其下级顶级域名服务器的域名及其IP地址,当低级域名服务器遇到无法解析的域名时,首先会向根域名服务器求助。
级别同顶级域,用于纪录注册在该顶级域名服务器上的所有二级域名并提供DNS查询服务。
为一个区域的主机提供DNS查询服务,如果查询结果为空,则通知发起请求的DNS用户应到哪个权限域名服务器进一步查询。
不在上图的域名服务器体系中,但在域名解析中扮演重要的角色。每主机发出的DNS域名查询请求首先都会发送到本地域名服务器。本地域名服务器可以设立在个人,大学,公司等各种范围内,又叫做首选DNS(很熟悉吧),就是我们计算机网络连接中的首选DNS:

 上图以用户访问头条网站为例,简明扼要的为大家讲述了用户输入网址到获取IP地址的全过程,下面我们来详细解释该过程:
上图以用户访问头条网站为例,简明扼要的为大家讲述了用户输入网址到获取IP地址的全过程,下面我们来详细解释该过程:
用户打开计算机,在浏览器中输入头条网址后计算机将向本地DNS服务器发起域名解析请求。本地DNS服务器通常由互联网服务提供商(ISP)提供,如三大运营商。
本地DNS服务器接收到用的DNS请求后,首先查询其自身缓存纪录中是否存在头条域名对应的IP地址,如果存在,则直接将该IP地址回传给用户计算机;否则,将进一步向根域名服务器发起求助。
由于根域名服务器只会纪录其下级的13个顶级域名服务器,而不会直接纪录域名与IP的映射关系,所以在接收到本地域名服务器的解析请求时,根域名服务器将告知本地服务器:“你所请求的域名由.com顶级域名服务器管理,其IP为xxx”。
本地DNS服务器进一步向.com顶级域名服务器发起域名解析请求,由于.com域名服务器也不会纪录域名与IP的映射关系,而是告知请求者去该域名所属的域服务器上查询,并给出其IP地址。
本地DNS服务器继续向域服务器发起头条域名解析请求,便会得到头条域名对应的IP地址,这时本地DNS服务器不仅会向用户计算机返回IP地址,同时在其自身缓存中增加头条域名与其IP的纪录,从而加快其他计算机获取头条域名对应IP的解析速度。


 一个多小时后。。。执行完了
一共3590条数据
一个多小时后。。。执行完了
一共3590条数据


 在tmp目录下会产生各种不同风格的图像。
在tmp目录下会产生各种不同风格的图像。




 搞定收工!
搞定收工!


 返回值说明:
返回值说明:
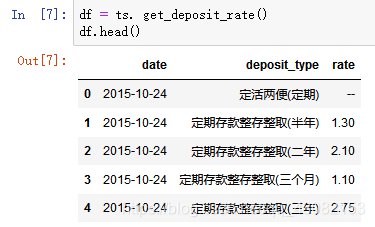
 其它的利率pro接口函数:
(1)pro.shibor_quote():Shibor报价数据
(2)pro.shibor_lpr():LPR贷款基础利率
(3)pro.Libor():伦敦同业拆借利率
(4)pro.Hibor():香港银行同业拆借利率
其它的利率pro接口函数:
(1)pro.shibor_quote():Shibor报价数据
(2)pro.shibor_lpr():LPR贷款基础利率
(3)pro.Libor():伦敦同业拆借利率
(4)pro.Hibor():香港银行同业拆借利率
 返回值说明:
参数 | 解释
-------- | -----
date | 日期
open | 开盘价
high | 最高价
close | 收盘价
low | 最低价
volume | 成交量
price_change | 价格变动
p_change | 涨跌幅
ma5 | 5日均价
ma10 | 10日均价
ma20 | 20日均价
v_ma5 | 5日均量
v_ma10 | 10日均量
v_ma20 | 20日均量
turnover | 换手率
返回值说明:
参数 | 解释
-------- | -----
date | 日期
open | 开盘价
high | 最高价
close | 收盘价
low | 最低价
volume | 成交量
price_change | 价格变动
p_change | 涨跌幅
ma5 | 5日均价
ma10 | 10日均价
ma20 | 20日均价
v_ma5 | 5日均量
v_ma10 | 10日均量
v_ma20 | 20日均量
turnover | 换手率 用pro接口函数pro.daily()获取的行情数据与用get_hist_data()函数获取的行情数据在结构上有些差别。函数pro.daily()的返回数据采用默认索引,交易日期作为一个字段(列)数据项,而get_hist_data()函数的返回数据以交易日期作为索引。
鉴于不同接口函数返回数据的结构存在或多或少的差别,因此在设计处理这些数据的程序时必须根据返回数据的结构选择合适的处理方法,或者对返回的数据项进行必要的修改,以满足其他数据处理语句的格式要求。
用pro接口函数pro.daily()获取的行情数据与用get_hist_data()函数获取的行情数据在结构上有些差别。函数pro.daily()的返回数据采用默认索引,交易日期作为一个字段(列)数据项,而get_hist_data()函数的返回数据以交易日期作为索引。
鉴于不同接口函数返回数据的结构存在或多或少的差别,因此在设计处理这些数据的程序时必须根据返回数据的结构选择合适的处理方法,或者对返回的数据项进行必要的修改,以满足其他数据处理语句的格式要求。 Tushare还提供股票交易行情的实时数据,即当天正在交易的股票价格数据。例如,通过get_realtime_quotes()函数获取的股票交易实时分笔数据可以包括股票当前时刻报价列表和成交价格等信息、五档买入报价和五档卖出价格等数据项,共有30余项信息。操作过程如下:
Tushare还提供股票交易行情的实时数据,即当天正在交易的股票价格数据。例如,通过get_realtime_quotes()函数获取的股票交易实时分笔数据可以包括股票当前时刻报价列表和成交价格等信息、五档买入报价和五档卖出价格等数据项,共有30余项信息。操作过程如下:  部分返回值说明:
参数 | 解释
-------- | -----
code | 股票代码
name | 股票名字
price | 当前价格
high | 今日最高价
low | 今日最低价
bid | 竞买价,即“买一”报价
ask | 竞卖价,即“卖一”报价
volume | 成交量 maybe you need do volume/100 amount,成交金额(元 CNY)
部分返回值说明:
参数 | 解释
-------- | -----
code | 股票代码
name | 股票名字
price | 当前价格
high | 今日最高价
low | 今日最低价
bid | 竞买价,即“买一”报价
ask | 竞卖价,即“卖一”报价
volume | 成交量 maybe you need do volume/100 amount,成交金额(元 CNY) 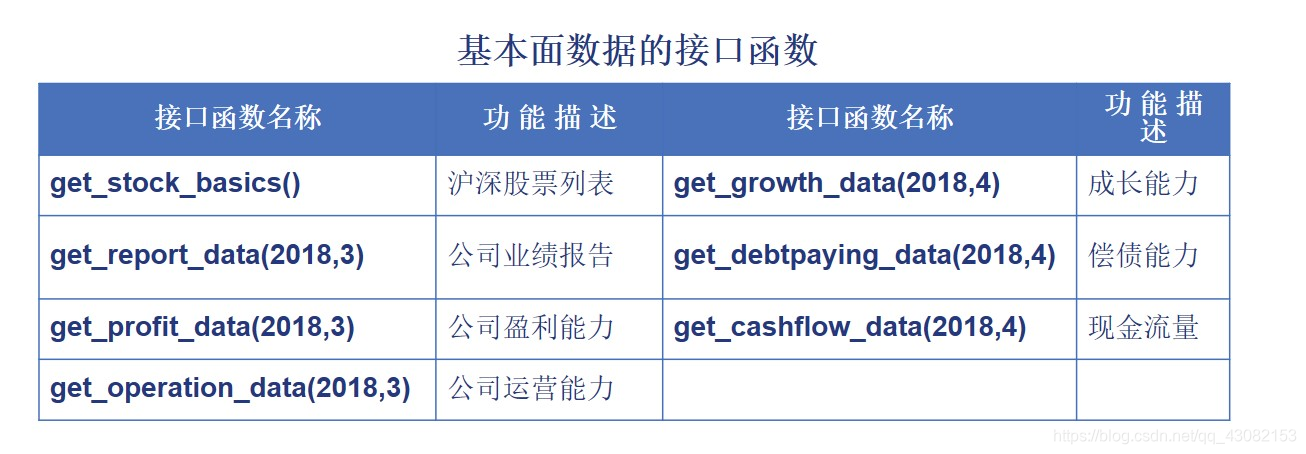
 下面两表列出的Tushare平台pro版接口函数index_basic()的输入参数和输出参数信息所示。
下面两表列出的Tushare平台pro版接口函数index_basic()的输入参数和输出参数信息所示。 



 数据集规模为3823x22,每行是一支股票的基本数据。字段详情请查看Tushare的网站。数据集字段详情查看
数据集规模为3823x22,每行是一支股票的基本数据。字段详情请查看Tushare的网站。数据集字段详情查看


 由上面的统计结果可见,经济越发达、越有活力的地区,上市公司的数量越多。读者还可以按行业进行类似的统计。数据框中的timeToMarket字段代表上市日期,其数据是格式形如“20190315”的整数类型。我们可以提取出其中的年份以统计每年的股票发行数量。
由上面的统计结果可见,经济越发达、越有活力的地区,上市公司的数量越多。读者还可以按行业进行类似的统计。数据框中的timeToMarket字段代表上市日期,其数据是格式形如“20190315”的整数类型。我们可以提取出其中的年份以统计每年的股票发行数量。 
 从图中可见IPO发行年份的几个高点和国内股票市场的几次牛市时间对应,熊市时发行数量跌入低谷。下面计算市场的平均市盈率pe,这是衡量股票市场估值的重要参数。
从图中可见IPO发行年份的几个高点和国内股票市场的几次牛市时间对应,熊市时发行数量跌入低谷。下面计算市场的平均市盈率pe,这是衡量股票市场估值的重要参数。  观察数据集发现,数据集中亏损股票的pe为0,因此考虑剔除亏损股票。
观察数据集发现,数据集中亏损股票的pe为0,因此考虑剔除亏损股票。  上面的pe是简单的算术平均,以市值为权重的加权pe可能更能准确地反映市场状况。由于下载的数据集中没有总市值和股票单价,因此只能根据现有的字段推算总市值。由某些列的值计算新的列值也是数据处理中常有的情况。这里推算总市值的依据如下:
股票单价 = 4esp(每股收益)pe(市盈率)
总市值 = 股票单价*totals总股本(亿元人民币)
数据集中每股收益esp是单个季度的收益,因此全年收益要乘以4。
上面的pe是简单的算术平均,以市值为权重的加权pe可能更能准确地反映市场状况。由于下载的数据集中没有总市值和股票单价,因此只能根据现有的字段推算总市值。由某些列的值计算新的列值也是数据处理中常有的情况。这里推算总市值的依据如下:
股票单价 = 4esp(每股收益)pe(市盈率)
总市值 = 股票单价*totals总股本(亿元人民币)
数据集中每股收益esp是单个季度的收益,因此全年收益要乘以4。 上面的计算结果反映了某次季报后的市场加权pe情况,结果和市场真实值相比有差异。这是因为股票的每个季度收益不同,因而不能简单按“4*单季收益”来计算全年收益。
上面的计算结果反映了某次季报后的市场加权pe情况,结果和市场真实值相比有差异。这是因为股票的每个季度收益不同,因而不能简单按“4*单季收益”来计算全年收益。
