“没事”语料库构建
用户需求:
想要构建一个关于“没事”这个口头话表达的语料库,大概几百条。数据来源不限,唯一要求是“没事”要出现在对话中。
解决方案:
1、设定数据源。要找到足够多的对话素材,最好的方法就是从小说中爬取。从互联网上随机下载一些素材。
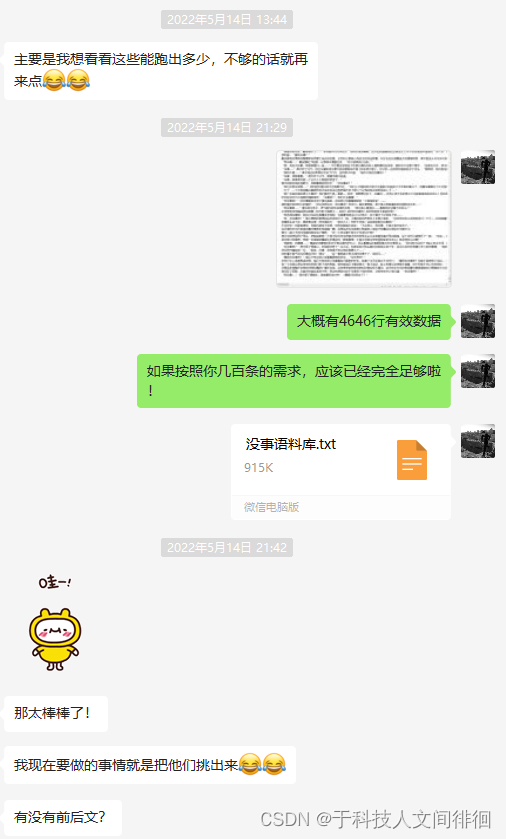
 2、初步清洗数据。通过Python检索爬取发现大概有4646行有效数据,如果按照你几百条的需求,应该已经完全足够啦!
2、初步清洗数据。通过Python检索爬取发现大概有4646行有效数据,如果按照你几百条的需求,应该已经完全足够啦!
 3、用户在查看数据示例后发现无法联系上线文语境分析出“没事”的具体含义,更改需求为:需要有检索出上下文的方法。
3、用户在查看数据示例后发现无法联系上线文语境分析出“没事”的具体含义,更改需求为:需要有检索出上下文的方法。
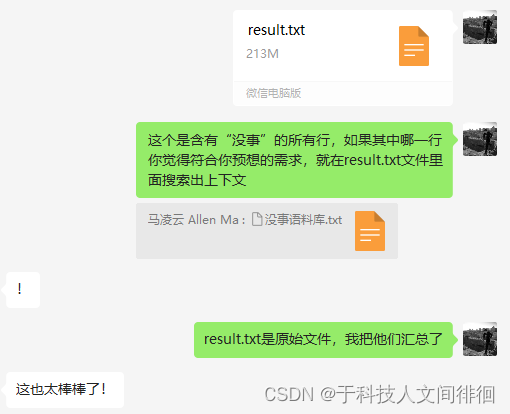
 4、为解决上述检索需求,最终尝试将所有TXT小说文件合并为一个大文本。这样用户在找到合适的“没事”对话后,就能在此大文本中搜索出对应的上下文,确定语境。
4、为解决上述检索需求,最终尝试将所有TXT小说文件合并为一个大文本。这样用户在找到合适的“没事”对话后,就能在此大文本中搜索出对应的上下文,确定语境。
 5、用户新的SOS。需求描述:"可不可以在提取的时候,只提取在引号里的没事,这样我可以确保是在对话中的,至少是言语的,因为现在的很多都是描述里的,比如a看b没事就走了,之类的,不符合“言语”。"
5、用户新的SOS。需求描述:"可不可以在提取的时候,只提取在引号里的没事,这样我可以确保是在对话中的,至少是言语的,因为现在的很多都是描述里的,比如a看b没事就走了,之类的,不符合“言语”。"
6、将之前导出的“没事”语料库做进一步清洗:匹配出同时包含“没事”和“引号”的数据行,另外导出为文件“没事语料库v1.1”。
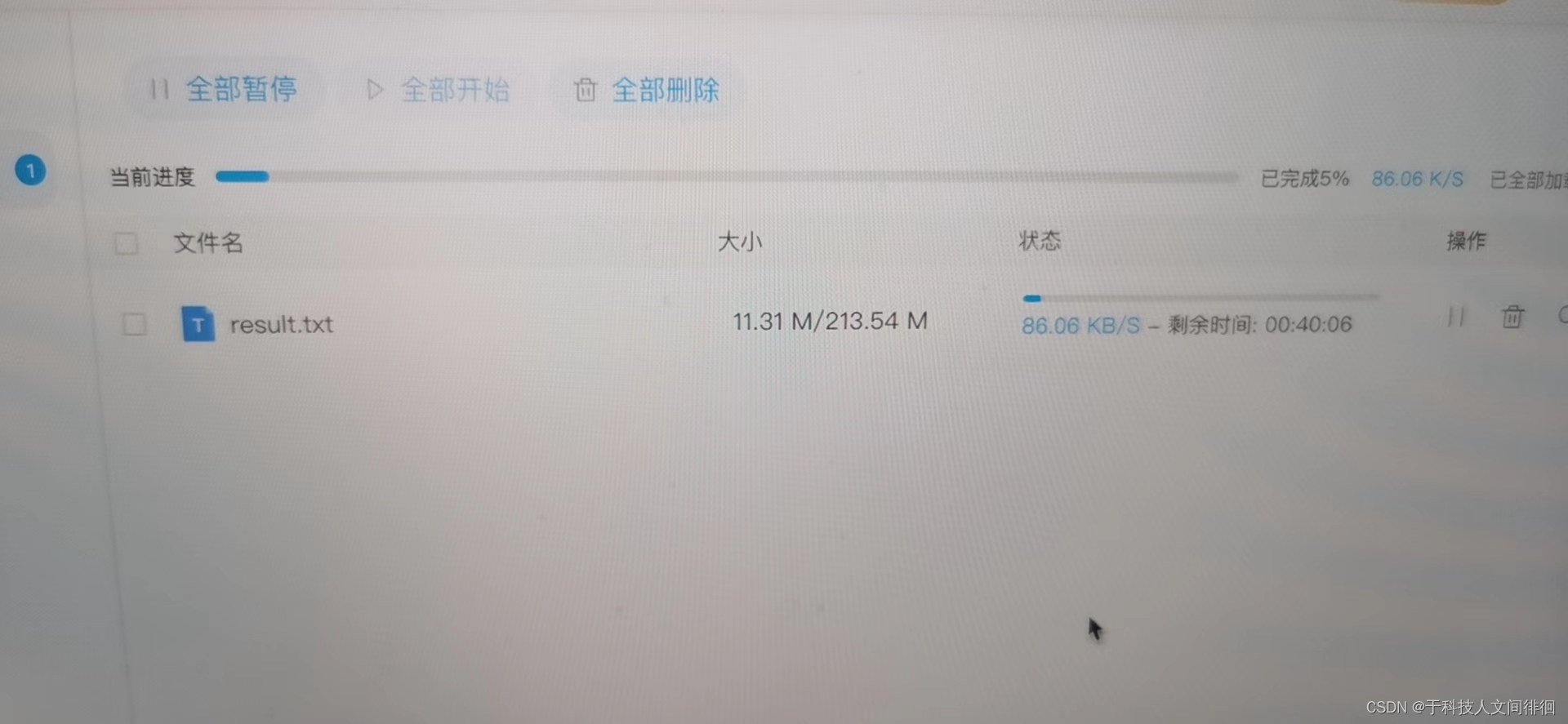
最后,由于用户身处海外,用微信传输大文件,太大下不下来,即使是换百度网盘传,下载速度也只有100KB/S,最终我选择了通过Google drive传输,技术人最后的倔强。