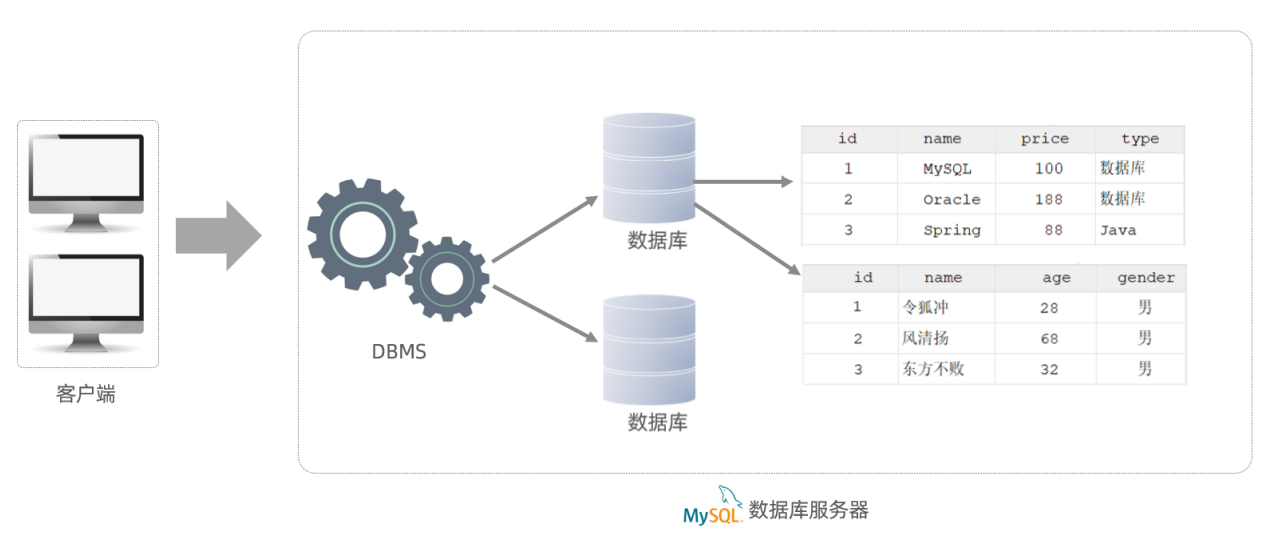
Foundation
Database
| Name | Full Name | Short Name |
|---|---|---|
| Database | A repository for storing data, where data is stored in an organized manner | DataBase (DB) |
| Database Management System | Large-scale software for manipulating and managing databases | DataBase Management System (DBMS) |
| SQL | A programming language for manipulating relational databases, defining a set of uniform standards for manipulating relational databases | Structured Query Language (SQL) |
Data Model
A relational database (RDBMS) is a database based on a relational model, consisting of a number of interconnected two-dimensional tables. By two-dimensional table, we mean a table consisting of rows and columns, which can be associated with a column of data in another table by a column, as shown below.
Features.
- Use of tables to store data in a uniform format for easy maintenance.
- using SQL language operation, the standard is uniform and easy to use.

The common MySQL, Oracle, DB2 and SQLServer are all relational databases, which store data based on two-dimensional tables.
Whichever relational database we use, we end up using the SQL language for uniform operations. This is because the SQL language, which we are going to learn, is the uniform standard for manipulating relational databases.
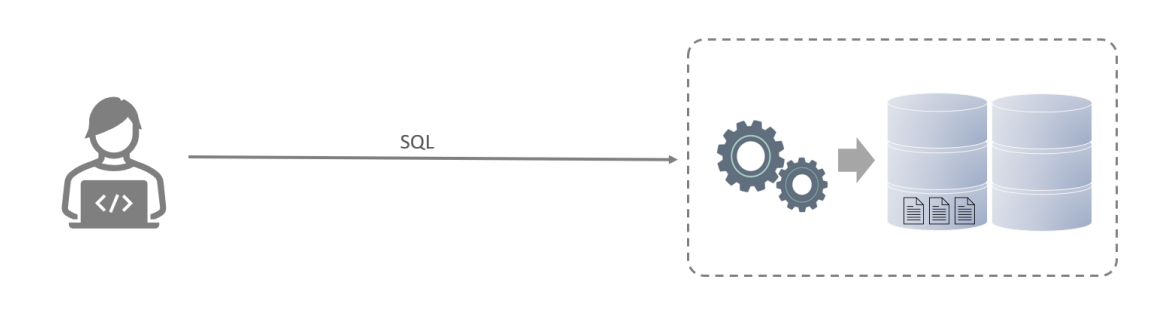
SQL
Structured Query Language. A programming language for manipulating relational databases, defining a set of uniform standards for manipulating relational databases.
- SQL statements can be written in single or multiple lines and terminated by a semicolon. 2.
- SQL statements can be space/indented to enhance readability. 3.
- SQL statements in MySQL database are case-insensitive and it is recommended to use upper case for keywords. 4.
- Comments: 1.
- single line comment: -- comment content or # comment content
- multi-line comments: / comment content /
SQL statements, according to their functions, are divided into four main categories: DDL, DML, DQL, DCL.
| Description | |
|---|---|
| DDL | Data Definition Language, used to define database objects (databases, tables, fields) |
| DML | Data Manipulation Language, used to add, delete and change data in database tables. |
| DQL | Data Query Language, used to query the database for table records |
| DCL | Data Control Language, used to create database users and control access rights to the database. |
DDL
Data Definition Language, used to define database objects (databases, tables, fields)
Database operations
Query all databases
SHOW DATABASES
Use a particular database
USE database name;
Query the current database
SELECT DATABASE();
Creating a database
The UTF8 character set is 3 bytes long, some symbols take up 4 bytes, so it is recommended to use the utf8mb4 character set when creating a database
CREATE DATABASE [ IF NOT EXISTS ] database name [ DEFAULT CHARSET character set ] [COLLATE sorting rules ];
Delete a database
DROP DATABASE [ IF EXISTS ] database name;
Data table operations
Creating a table
The last field is not followed by a comma.
CREATE TABLE table name (
Field 1 Field 1 type [COMMENT Field 1 comment],
Field 2 Field 2 type [COMMENT Field 2 comment],
Field 3 Field 3 type [COMMENT Field 3 comment],
...
Field n Field n type [COMMENT Field n comment]
) [ COMMENT table comment ];
Querying a table structure
DESC table name;
Query all tables in the current database, must be in the database
SHOW TABLES;
Query a table build statement for a table
SHOW CREATE TABLE table name;
Add fields to a table
ALTER TABLE table name ADD field name type (length) [COMMENT comment] [constraint];
-- for example
ALTER TABLE emp ADD nickname varchar(20) COMMENT 'User nickname';
Modify the data type
ALTER TABLE table name MODIFY field name new data type (length);
-- for example
ALTER TABLE emp MODIFY nickname varchar(30);
Modify the field name and field type
ALTER TABLE table name CHANGE old field name new field name type (length) [COMMENT comment] [constraint];
-- for example
ALTER TABLE emp CHANGE nickname name varchar(40);
Delete a field
ALTER TABLE table name DROP field name;
-- for example
ALTER TABLE emp drop nickname;
Modify a table name
ALTER TABLE table name RENAME TO new table name;
-- for example
ALTER TABLE emp RENAME TO empNew;
Delete a table
DROP TABLE [IF EXISTS] Table name;
-- for example
DROP TABLE [IF EXISTS] emp;
Delete the table and recreate it
TRUNCATE TABLE table name;
-- for example
TRUNCATE TABLE emp;
DML
Data Manipulation Language, used to add, delete and change data in database tables
String and date type data should be enclosed in inverted commas
The size of the inserted data should be within the specified range of the field
Specify the field to add data to
INSERT INTO table name (field name 1, field name 2, ...) VALUES (value1, value2, ...) ;
Add data for all fields
INSERT INTO table name VALUES (value 1, value 2, ...) ;
Adding data in batches
--Specify the fields
INSERT INTO table name (field name 1, field name 2, ...) VALUES (value1, value2, ...) , (value1, value2, ...) , (value1, value2, ...) ;
--all fields
INSERT INTO table name VALUES (value1, value2, ...) , (value1, value2, ...) , (value1, value2, ...) ;
Modifying data
UPDATE table name SET field name 1 = value 1, field name 2 = value 2, ... [ WHERE condition ];
-- for example
UPDATE emp SET nickname = 'Lakshin Lake' WHERE id = 1;
Delete data
DELETE FROM table name [ WHERE condition ];
DQL
Data Query Language, used to query a database for records in a table
Basic queries
SELECT
List of fields
FROM
Table name field
WHERE
List of conditions
GROUP BY
List of grouped fields
HAVING
List of conditions after grouping
ORDER BY
Sorted list of fields
LIMIT
Pagination parameters
Query all fields
SELECT * FROM table name;
-- Instead of *, it is recommended to write out each field in practice
SELECT id,name,age... FROM emp;
Query result fields with aliases
SELECT field1 [ AS alias1 ], field2 [ AS alias2 ], field3 [ AS alias3 ], ... FROM table name;
SELECT field1 [ AS alias1 ], field2 [ AS alias2 ], field3 [ AS alias3 ], ... FROM table name;
Removing duplicate rows
SELECT DISTINCT field list FROM table name;
Conditional queries
SELECT LIST OF FIELDS FROM table name WHERE list of conditions;
List of Conditions
| Compare Operators | Function |
|---|---|
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| = | equal to |
<> or ! = | not equal to |
| BETWEEN ... AND ... | within a range (with minimum and maximum values) |
| IN(...) | the value in the list after in, multiple choice, or meaning |
| LIKE placeholder | fuzzy match (_ matches a single character, % matches any character) |
| IS NULL | is NULL |
| logical operators | function | ||
|---|---|---|---|
| AND or && | and (multiple conditions hold simultaneously) | ||
| OR or \ | \ | or (any one of several conditions holds) | |
| NOT or ! | NOT, NOT |
-- Age equals 30
select * from emp where age = 30;
-- no idcard
select * from emp where idcard is null or idcard = '';
-- with idcard
select * from emp where idcard;
select * from emp where idcard is not null;
-- not equal to
select * from emp where age ! = 30;
-- age between 20 and 30
select * from emp where age between 20 and 30;
select * from emp where age >= 20 and age <= 30;
-- The following statement does not report an error, but does not give any information, so be sure to start small and then write big
select * from emp where age between 30 and 20;
-- female gender and age less than 30
select * from emp where age < 30 and gender = 'female';
-- age equal to 25 or 30 or 35
select * from emp where age = 25 or age = 30 or age = 35;
select * from emp where age in (25, 30, 35);
-- name as two characters
select * from emp where name like '__';
-- the first character of the name is bell
select * from emp where name like 'Zhong%';
-- the last word of the name is 雪
select * from emp where name like '% snow';
-- idcard last is X
select * from emp where idcard like '%X';
Aggregate queries
Computes a column of data as a whole, vertically. Acts directly on the fields.
SELECT Aggregate function (list of fields) FROM table name;
Common aggregation functions are listed below. Note: all null values do not participate in aggregation operations.
| Functions | Function |
|---|---|
| count | Number of statistics |
| max | maximum |
| min | min |
| avg | average |
| sum | summing |
-- Counting the number of employees in a company
select count(id) from emp;
-- Statistic of the average age of the company
select avg(age) from emp;
-- Statistics for the sum of the ages of employees in Xi'an
select sum(age) from emp where workaddr = 'Xi'an';
Query by group
SELECT list of fields FROM table name [ WHERE conditions ] GROUP BY grouped field names [ HAVING filter conditions after grouping ];
Grouping is often accompanied by aggregation
Differences between where and having.
- The timing of execution is different: where is filtered before grouping and does not participate in grouping without satisfying the where condition; having is filtered after grouping.
- Judgment conditions are different: where cannot make judgments about aggregation functions, whereas having can.
Note that
- Execution order: where > aggregate function > having
- After grouping, query fields are generally aggregated functions and grouped fields, querying other fields has no meaning
-- count the number of males and females based on gender grouping (only the number of groups is displayed, not which is male and which is female)
select count(*) from emp group by gender;
-- count the number of males and females grouped by gender
select gender, count(*) from emp group by gender;
-- count the average age of males and females according to their gender group
select gender, avg(age) from emp group by gender;
-- age less than 45 and grouped by work address, get number of employees
select workaddr, count(*) from emp where age < 45 group by workaddr;
-- age < 45 and group by workaddr, get the number of employees at workaddr greater than or equal to 3
select workaddr, count(*) address_count from emp where age < 45 group by workaddr having address_count >= 3;
Sorted queries
If it is a multi-field sort, only sort based on the second field when the first field has the same value
SELECT list of fields FROM table name ORDER BY field 1 sort by 1, field 2 sort by 2;
Sort by
- ASC: ascending (default)
- DESC: descending order
-- Sort by age in ascending order
select * from emp order by age ASC;
select * from emp order by age;
-- Sort the company's employees in ascending order by age, with the same age, then sort in descending order by entry time
select * from emp order by age ASC, entrydate DESC;
Paging query
SELECT list of fields FROM table name LIMIT starting index, number of rows to query;
- The starting index starts at 0, so there is a formula here, starting index = (query page - 1) * number of records per page
- Paging queries are a database dialect, different databases have different implementations, MySQL is LIMIT
- If the query is for the first page of data, the starting index can be omitted and simply abbreviated to LIMIT 10
-- Query the first page of data, displaying 10 items
select * from emp limit 0, 10;
-- Query the second page, displaying 10 items per page
select * from emp limit 10, 10;
DQL exercises
DQL is written in the following order.
SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY -> LIMIT
DQL execution order.
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT

Complete the following DQL statements as required
-- 1. Query the information of employees whose age is 20,21,22,23.
select * from emp where age in(20,21,22,23);
-- 2. Search for employees whose gender is male and whose age is within 20-40 years (inclusive) and whose name is three characters.
select * from emp where gender = 'male' and age between 20 and 40 and name like '____';
-- 3. Count the number of male and female employees in the employee table who are less than 60 years of age.
select gender, count(*) from emp where age < 60 group by gender;
-- 4. Search the names and ages of all employees less than or equal to 35 years of age, and sort the results in ascending order by age, and if the same age, sort in descending order by time of entry.
select name, age from emp where age < 35 order by age ASC, entrydata DESC;
-- 5, query the gender of men, and age in the 20-40 years (including) the first five employees information, the results of the query in ascending order by age, the same age in ascending order by entry time.
select * from emp where (gender = 'male') and (age >= 20 and age <= 40) order by age ASC,entrydata DESC limit 5;
DCL
Data Control Language, used to create database users and control access to the database
User management
Query users
use mysql;
select * from user;
Create a user
CREATE USER 'username'@'hostname' IDENTIFIED BY 'password';
Change user password
ALTER USER 'username'@'hostname' IDENTIFIED WITH mysql_native_password BY 'new password';
Deletes the password used by
DROP USER 'username'@'hostname';
Example
-- Create user lxh, accessible only on the current host localhost
create user 'lxh'@'localhost' identified by '123456';
-- create user test, can be accessed on any host, use % wildcard
create user 'lxh'@'%' identified by '123456';
create user 'lxh' identified by '123456';
-- change password
alter user 'lxh'@'localhost' identified with mysql_native_password by '123';
-- delete user
drop user 'lxh'@'localhost';
Permissions management
The common permissions are as follows, you need Baidu for more details.
| Permissions | Description |
|---|---|
| ALL, ALL PRIVILEGES | All Permissions |
| SELECT | Query Data |
| INSERT | Insert data |
| UPDATE | Modify Data |
| DELETE | Delete data |
| ALTER | Modify Table |
| DROP | Delete Database/Table/View |
| CREATE | Create Database/Table |
-- Query Permissions.
SHOW GRANTS FOR 'username'@'hostname';
-- Granting permissions.
GRANT Permission List ON database name. table name TO 'username'@'hostname';
-- Revoke permissions.
REVOKE permission list ON database name. TABLE NAME FROM 'username'@'hostname';
-- Caution.
-- Multiple permissions are separated by commas
-- When authorising, database names and table names can be wildcarded with * to represent all
A function is a piece of program or code that can be called directly by another program.
In an enterprise OA or other human resources system, there is often a function that allows each employee to log in and see the number of days they have been on the job. In the database, the date of entry is stored, e.g. 2000-11-12, but what about a quick calculation of the number of days? 2. In a business requirement such as a report, we need to show the distribution of the score levels of the students. In the database, the students' score values are stored, e.g. 98/75. How can we quickly determine the grade of the score? How can we quickly determine the grade of a student?
All these requirements can be easily solved in MySQL functions.
String Functions
Commonly used string functions
| Functions | Function |
|---|---|
| CONCAT(s1, s2, ..., sn) | String concatenation, concatenating s1, s2, ..., sn into a string |
| LOWER(str) | convert all strings to lowercase |
| UPPER(str) | convert the string to uppercase |
| LPAD(str, n, pad) | left padding, padding the left side of str with the string pad to reach n string lengths |
| RPAD(str, n, pad) | right padding, padding the right side of str with the string pad to reach n string lengths |
| TRIM(str) | removes the spaces at the beginning and end of the string |
| SUBSTRING(str, start, len) | returns a string of len lengths from the start position of str, starting at index 1 |
For example, the work number of employee number 1 should be 00001.
update emp set workno = LPAD(workno,5,'0');
Numeric functions
Commonly used numeric functions
| Functions | Function |
|---|---|
| CEIL(x) | rounds up |
| FLOOR(x) | rounding down |
| MOD(x, y) | returns the modulus of x/y |
| RAND() | return a random number within 0~1 |
| ROUND(x, y) | the rounded value of the parameter x, retaining y decimal places |
Example: Generate a six-digit random verification code via a database function.
-- Get 0~1 by rand(), multiply by 1000000, just by rounding. If it is less than 6 digits, then make up 0
select lpad(round(rand()*1000000, 0), 6, '0');
Date functions
Common Date Functions
| Functions | Functions |
|---|---|
| CURDATE() | Returns the current date |
| CURTIME() | returns the current time |
| NOW() | Returns the current date and time |
| YEAR(date) | Get the year of the specified date |
| MONTH(date) | Get the month of the specified date |
| DAY(date) | Get the date of the specified date |
| DATE_ADD(date, INTERVAL expr type) | return a date/time value plus an interval expr |
| DATEDIFF(date1, date2) | returns the number of days between the start time of date1 and the end time of date2 |
Example: Query the number of days all employees have been on board, and sort backwards based on the time they were on board
select name, datediff(curdate(), entrydate) as dates from emp order by dates desc;
Process functions
Common Process Functions
| Functions | Function |
|---|---|
| IF(value, t, f) | Returns t if value is true, otherwise returns f |
| IFNULL(value1, value2) | If value1 is not null, return value1, otherwise return value2 |
| CASE WHEN [val1] THEN [res1] ... ELSE [default] END | If val1 is true, return res1, ... otherwise return default default |
| CASE [expr] WHEN [val1] THEN [ res1 ] ... ELSE [ default ] END | If expr is equal to val1, return res1, ... else default default |
select
name,
if(age between 14 and 28, 'youth', 'other')
from emp;
select
name,
(case workaddress when 'Beijing' then 'Tier 1 city' when 'Shanghai' then 'Tier 1 city' else 'Tier 2 city' end) as 'work address'
from employee;
Constraints are applied to fields in a table to restrict the data stored in the table. The purpose is to ensure that the data in the data is correct, valid and complete.
Constraints can be added at the time of table creation / modification.
Common constraints.
| Constraint | Description | Keyword |
|---|---|---|
| Non-Null Constraint | Restricts the data in the field to not be null | NOT NULL |
| Unique Constraint | Ensures that all data in the field is unique and non-repetitive | UNIQUE |
| PRIMARY KEY (self-incrementing: AUTO_INCREMENT) | ||
| DEFAULT | Default constraint | When saving data, if no value is specified for the field, the default value is used |
| CHECK constraint (since version 8.0.1) | Ensures that a field value meets a certain condition | CHECK |
| FOREIGN KEY | A foreign key constraint is used to establish a link between data in two charts to ensure data consistency and integrity. |
Common Constraints
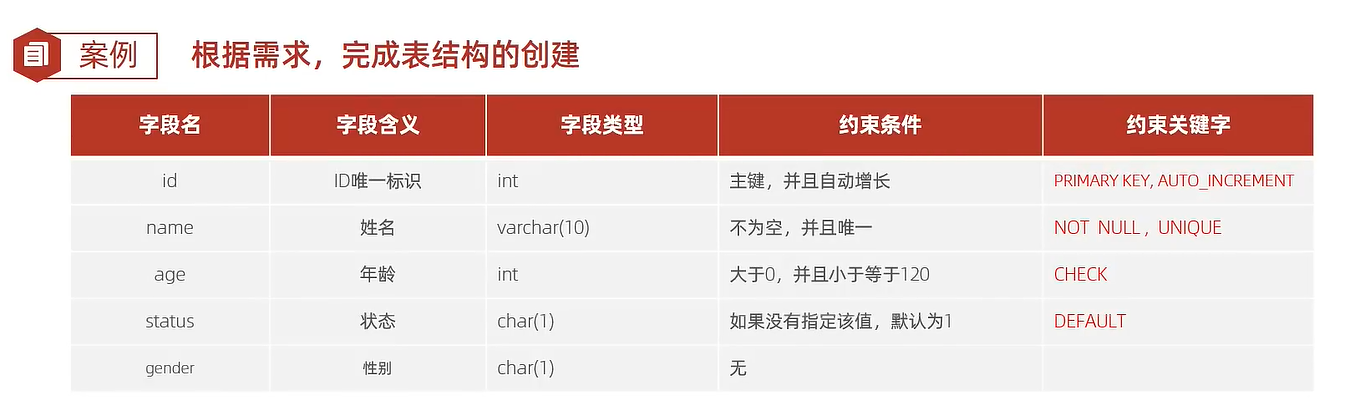
create table user(
id int primary key auto_increment comment 'primary key id',
name varchar(10) not null unique comment 'name',
age int check(age between 0 and 120) comment 'age',
status char(1) default '1' comment 'status',
gender char(1) comment 'gender'
) comment 'user table';
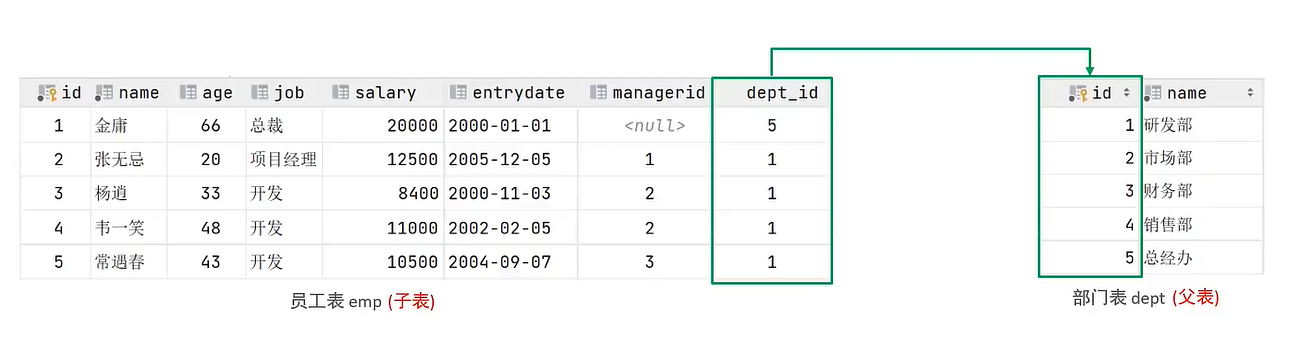
Foreign Key Constraints
A foreign key constraint is used to allow a join to be made between data in two tables, thus ensuring data consistency and integrity.
-- Adding a foreign key when creating a table
CREATE TABLE table name (
Field Name Field Type,
...
[CONSTRAINT] [foreign key name] FOREIGN KEY(foreign key field name) REFERENCES primary table (primary table column name)
);
-- Add a foreign key to a table
ALTER TABLE table name ADD CONSTRAINT foreign key name FOREIGN KEY (foreign key field name) REFERENCES main table (main table column name);
-- Delete a foreign key
ALTER TABLE table name DROP FOREIGN KEY foreign key name;
Example: add a foreign key to emp table, dept_id relates to the id in dep
alter table emp add constraint fk_emp_dept_id foreign key dept_id references dep(id);
delete / update behaviour
The constraint behaviour that occurs when a table is added with a foreign key and then the data of the parent table is deleted is known as the delete/update behaviour. There are several common types.
| Behaviour | Description |
|---|---|
| NO ACTION | When deleting/updating a corresponding record in the parent table, first check whether the record has a corresponding foreign key and if so, disallow the deletion/update (in line with RESTRICT) |
| RESTRICT | When deleting/updating a corresponding record in the parent table, first check if the record has a corresponding foreign key, and if so, disallow the deletion/update (consistent with NO ACTION) |
| CASCADE | When deleting/updating a corresponding record in the parent table, first check if the record has a corresponding foreign key, and if so, also delete/update the record whose foreign key is in the child table. |
| SET NULL | When deleting/updating a corresponding record in the parent table, first check if the record has a corresponding foreign key, and if so, set the foreign key in the child table to null (requiring the foreign key to be allowed to be null) |
| SET DEFAULT | Set the foreign key to a default value in the child table when there are changes to the parent table (not supported by Innodb) |
ALTER TABLE table name ADD CONSTRAINT foreign key name FOREIGN KEY (foreign key field) REFERENCES primary table name (primary table field name) ON UPDATE behaviour ON DELETE behaviour;
-- is actually an additional definition when adding a foreign key
-- e.g. when deleting/updating a corresponding record in the parent table, first check whether the record has a corresponding foreign key, and if so also delete/update the record whose foreign key is in the child table
alter table emp add constraint fk_emp_dept_id foreign key dept_id references dep(id) on update cascade on delete cascade;
In project development, when designing the database table structure, the table structure will be analysed and designed according to the business requirements and the relationship between the business modules. As the businesses are interrelated, there are various links between the various table structures, which are basically divided into three types.
Multi-table relationships
One-to-many
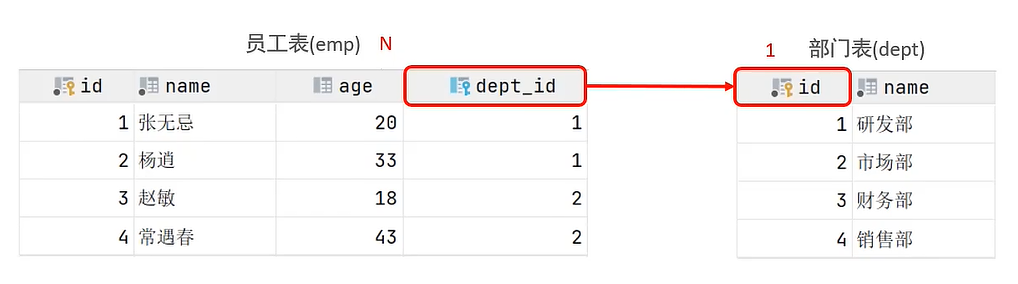
Case: Department and employee
Relationships: one department corresponds to multiple employees, one employee corresponds to one department
Implementation: create a foreign key on the side of many, pointing to the primary key of one
Many-to-many
Case: Student and course
Relationship: A student can take more than one course, and a course can be taken by more than one student
Implementation: create a third intermediate table with at least two foreign keys, each associated with two primary keys

One-to-one
Case: user and user details
Relationship: one-to-one relationship, mostly used for single-table splitting, where the base fields of one table are placed in one table and the other detail fields are placed in another table to improve operational efficiency
Implementation: add a foreign key to either party, associate the primary key of the other party, and set the foreign key to be unique (UNIQUE)

Multi-table queries
Refers to querying for the desired data from multiple tables.
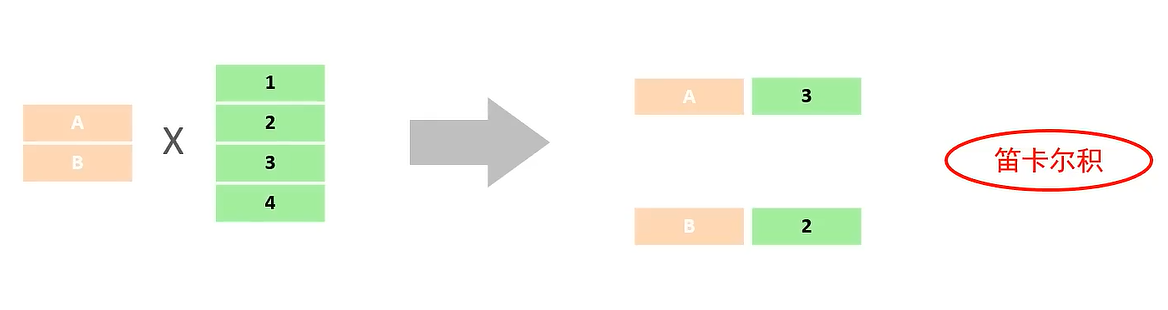
Cartesian product: A Cartesian product is all combinations of the sets of two sets A and B in mathematics. (In a multi-table query, it is necessary to eliminate invalid Cartesian Cartesian product)
Example: select * from employee, dept; The result of the query is the product of the two tables.
Eliminate Cartesian products: select * from employee, dept where employee.dept = dept.id;
Before we do the multi-table query test, let's prepare the data table.
-- Prepare the data
create table dept(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment 'department name'
) comment 'department table';
create table emp(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment 'Name',
age int comment 'age',
job varchar(20) comment 'Position',
salary int comment 'Salary',
entrydate date comment 'time of entry',
managerid int comment 'immediate supervisor ID',
dept_id int comment 'Department ID'
) comment 'Employee table';
-- add a foreign key
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
INSERT INTO dept (id, name) VALUES (1, 'R&D'), (2, 'Marketing'), (3, 'Finance'), (4, 'Sales'), (5, 'General Manager's Office'), (6, 'HR');
INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id) VALUES
(1, 'jinyong', 66, 'president',20000, '2000-01-01', null,5),
(2, 'Zhang Wuji', 20, 'Project Manager',12500, '2005-12-05', 1,1),
(3, 'Yang Yi', 33, 'Development', 8400, '2000-11-03', 2,1),
(4, 'Wei Yixiao', 48, 'Development',11000, '2002-02-05', 2,1),
(5, 'Chang Yi Chun', 43, 'Development',10500, '2004-09-07', 3,1),
(6, 'Xiao Zhao', 19, 'Programmer Encourager',6600, '2004-10-12', 2,1),
(7, 'Extinction', 60, 'Finance Director',8500, '2002-09-12', 1,3),
(8, 'Zhou Zhiyao', 19, 'Accountant',48000, '2006-06-02', 7,3),
(9, 'Ding Minjun', 23, 'Cashier',5250, '2009-05-13', 7,3),
(10, 'Zhao Min', 20, 'Director of Marketing',12500, '2004-10-12', 1,2),
(11, 'Deerstalker', 56, 'Staff',3750, '2006-10-03', 10,2),
(12, 'The Crane Penman', 19, 'Staff',3750, '2007-05-09', 10,2),
(13, 'Fang Dongbai', 19, 'Staff',5500, '2009-02-12', 10,2),
(14, 'Zhang Sanfeng', 88, 'Sales Director',14,000, '2004-10-12', 1,4),
(15, 'Yu Lianzhou', 38, 'Sales',4600, '2004-10-12', 14,4),
(16, 'Song Yuanqiao', 40, 'Sales',4600, '2004-10-12', 14,4),
(17, 'Chen You Lang', 42, null,2000, '2011-10-12', 1,null);
Inner join queries
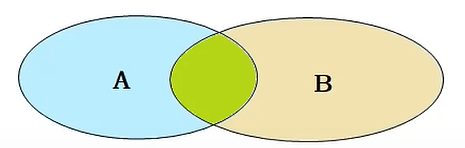
An inner join query is the part of the intersection of two tables.
Implicit inner join.
SELECT field list FROM table 1, table 2 WHERE condition ... ;
Explicit inner join.
SELECT list of fields FROM table 1 [ INNER ] JOIN table 2 ON join condition ... ;
SQL Explicit performance is higher than implicit
-- Query the name of each employee, and the name of the associated department (implicit inner join query)
select emp.name, dept.name from emp, dep where emp.dept_id = dept.id;
select e.name, d.name from emp e, dep d where e.dept_id = d.id;
-- Query each employee's name, and the name of the associated department (explicit inner join)
select emp.name, dept.name from emp inner join dept on emp.dept_id = dept.id;
select e.name, d.name from emp e inner join dept d on e.dept_id = d.id;
Outer join query
-- Query all the data in the emp table and the corresponding department information (left outer join)
select e.*, d.* from emp e left join dept d on e.dept_id = d.id;
-- Query all the data in the dept table and the corresponding employee information (right outer join)
select d.name, e.* from emp e right join dept d on e.dept_id = d.id;
-- As you can see above, the left join queries employees without dept and the right join queries dept without employee
Self-joining queries
A self-join query is a join query on itself, treating itself as another table, so it requires must use a table alias, self-join queries can be inner join queries or outer join queries.
-- Query employees and their leaders
select a.name 'employee', b.name 'leader' from emp a, emp b where a.managerid = b.id;
-- Query all employees emp and their leader's name, if the employee does not have a leader, you also need to query it
select a.*, b.name 'leader' from emp a left join emp b on a.managerid = b.id;
Union query union
A union query is a query that combines the results of multiple queries to form a new set. Union queries are more efficient than using or and do not invalidate indexes. For a union query, the number of columns in multiple tables must be the same and the field types must be the same. union all will merge all the data together directly, and union will de-duplicate the merged data.
SELECT list of fields FROM table A ...
UNION [ALL]
SELECT list of fields FROM table B ...
-- Search for all employees whose salary is less than 5000, and all employees who are older than 50.
select * from emp where salary < 5000
union
select * from emp where age > 50
-- Using UNION ALL will give duplicate results, UNION will not.
Subqueries
A nested SELECT statement within a SQL statement is called a nested query, also known as a subquery.
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2);
Statements external to a subquery can be any of INSERT / UPDATE / DELETE / SELECT
Subqueries can be classified according to their results as
- Scalar subqueries (subquery results in a single value)
- Column subqueries (subquery results in a single column)
- Row subquery (subquery results in a row)
- Table subquery (subquery results in multiple rows and columns)
Subqueries can be classified according to their position as
- AFTER WHERE
- after FROM
- after SELECT
Scalar subqueries
Subqueries return a single value (number, string, date, etc.).
Common operators: - < > >= < <=
-- Query all employees in the sales department
select id from dept where name = 'Sales Department';
-- Query employee information based on the department ID of the sales department
select * from emp where dept = 4;
-- merge into scalar subquery
select * from emp where dept = (select id from dept where name = 'Sales Department');
-- Query the information of new employees who have joined since Li Bai joined
select * from emp where entrydate > (select entrydate from employee where name = 'Li Bai');
Column queries
The result returned is a single column (can be multiple rows).
Common operators.
| operator | description |
|---|---|
| IN | Within the specified set, multiple selections |
| NOT IN | Not in the specified set range |
| ANY | The subquery returns a list of items, any one of which is sufficient |
| SOME | is the same as ANY, you can use ANY wherever you use SOME |
| ALL | All of the values in the subquery return list must be satisfied |
-- Query all the employees in the Sales and Marketing departments
select * from emp where dept_id in(select id from dept where name = 'Sales Department' or name = 'Marketing Department');
-- Query the information of employees whose salary is higher than all the employees in the finance department
select * from emp where salary > all(select salary from emp where dept_id = (select id from dept where name = 'Finance Department'));
-- Query the information of employees with higher salary than any one in the R&D department
select * from emp where salary > any(select salary from emp where dept_id = (select id from dept where name = 'R&D'));
Row subquery
The result returned is a single row (can be multiple columns).
Common operators: =, <, >, IN, NOT IN
-- Query for employees with the same salary and immediate supervisor as Li Bai
select * from emp where (salary, manager) = (12500, 1);
select * from emp where (salary, manager) = (select salary, manager from emp where name = 'Li Bai');
Table subquery
Returns results with multiple rows and columns Common operators: IN
-- Query for employees with the same job and salary as xx1, xx2
select * from emp where (job, salary) in (select job, salary from emp where name = 'xxx1' or name = 'xxx2');
-- Query employees whose start date is after 2022-01-01, and their department information
select e.*, d.* from (select * from emp where entrydate > '2022-01-01') as e left join dept as d on e.dept_id = d.id;
Multi-table exercise
Data preparation.
-- Prepare the data
create table dept(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment 'department name'
) comment 'department table';
create table emp(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment 'Name',
age int comment 'age',
job varchar(20) comment 'Position',
salary int comment 'Salary',
entrydate date comment 'time of entry',
managerid int comment 'immediate supervisor ID',
dept_id int comment 'Department ID'
) comment 'Employee table';
-- add a foreign key
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
INSERT INTO dept (id, name) VALUES (1, 'R&D'), (2, 'Marketing'), (3, 'Finance'), (4, 'Sales'), (5, 'General Manager's Office'), (6, 'HR');
INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id) VALUES
(1, 'jinyong', 66, 'president',20000, '2000-01-01', null,5),
(2, 'Zhang Wuji', 20, 'Project Manager',12500, '2005-12-05', 1,1),
(3, 'Yang Yi', 33, 'Development', 8400, '2000-11-03', 2,1),
(4, 'Wei Yixiao', 48, 'Development',11000, '2002-02-05', 2,1),
(5, 'Chang Yi Chun', 43, 'Development',10500, '2004-09-07', 3,1),
(6, 'Xiao Zhao', 19, 'Programmer Encourager',6600, '2004-10-12', 2,1),
(7, 'Extinction', 60, 'Finance Director',8500, '2002-09-12', 1,3),
(8, 'Zhou Zhiyao', 19, 'Accountant',48000, '2006-06-02', 7,3),
(9, 'Ding Minjun', 23, 'Cashier',5250, '2009-05-13', 7,3),
(10, 'Zhao Min', 20, 'Director of Marketing',12500, '2004-10-12', 1,2),
(11, 'Deerstalker', 56, 'Staff',3750, '2006-10-03', 10,2),
(12, 'The Crane Penman', 19, 'Staff',3750, '2007-05-09', 10,2),
(13, 'Fang Dongbai', 19, 'Staff',5500, '2009-02-12', 10,2),
(14, 'Zhang Sanfeng', 88, 'Sales Director',14,000, '2004-10-12', 1,4),
(15, 'Yu Lianzhou', 38, 'Sales',4600, '2004-10-12', 14,4),
(16, 'Song Yuanqiao', 40, 'Sales',4600, '2004-10-12', 14,4),
(17, 'Chen You Lang', 42, null,2000, '2011-10-12', 1,null);
create table salgrade(
grade int,
losal int,
hisal int
) comment 'Salary grade table';
insert into salgrade values (1,0,3000);
insert into salgrade values (2,3001,5000);
insert into salgrade values (3,5001,8000);
insert into salgrade values (4,8001,10000);
insert into salgrade values (5,10001,15000);
insert into salgrade values (6,15001,20000);
insert into salgrade values (7,20001,25000);
insert into salgrade values (8,25001,30000);
sql exercises
with explicit inner joins
-- 1. Query employee's name, age, job, department information (implicit inner join)
select e.name, e.age, e.job, d.name from emp e, dept d where e.dept_id = d.id;
-- 2. Query the name, age, job and department of an employee who is less than 30 years old (explicit inner join)
select e.name, e.age, e.job, d.name from emp e inner join dept d on e.dept_id = d.id where e.age < 30;
-- 3. Query the department ID, department name of an employee who has
-- Use inner join to allow empty data to be filtered
-- Use distinct to filter the same data
select distinct d.id, d.name from dept d inner join emp e on d.id = e.dept_id;
-- 4. search for all employees over 40 years of age, and their department name; if the employee is not assigned a department, you need to show it too
select e.*, d.name from emp e left join dept d on e.dept_id = d.id where e.age > 40;
-- 5. Query the pay grade of all employees
select e.name, e.salary, s.grade from emp e inner join salgrade s on e.salary between s.losal and s.hisal;
-- 6. query all employees of "R&D Department" and their salary grades
select d.name 'department', e.*, s.grade from emp e inner join salgrade s on e.salary between s.losal and s.hisal inner join dept d on e.dept_id = d.id where d.name = 'R&D department';
-- 7. Query the average salary of employees in the "R&D Department"
select d.name 'department', avg(e.salary) from emp e inner join dept d on e.dept_id = d.id where d.name = 'R&D Department';
-- 8. Query the information of employees whose salary is higher than "extinct".
select * from emp where salary > (select salary from emp where name = 'extinct');
-- 9. Query information about employees with higher than average salary
select * from emp where salary > (select avg(emp.salary) from emp);
-- 10. query the information of employees whose salary is lower than the average salary of the department
select * from emp e2 where e2.salary < (select avg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id );
-- 11. query all departments, and count the number of employees in the department
select d.*, (select count(*) from emp e where e.dept_id = d.id) 'headcount' from dept d;

A transaction is a collection of operations that are an indivisible unit of work, and a transaction commits or revokes an operation request to the system by taking all operations together as a whole
These operations either succeed or fail at the same time.
By default MysQL's transactions are automatically committed, when a DML statement is executed, MySQL implicitly commits the transaction immediately.
Transactional Operations
The transaction is demonstrated as follows, if an error terminal is reported between steps 2-3, then Zhang San loses 1000; while Li Si does not receive 1000.
-- 1. Query Zhang San's account balance
select * from account where name = 'Zhang San';
-- 2. set Zhang San account balance -1000
update account set money = money - 1000 where name = '张三';
-- 3. update the balance of Li Si's account +1000
update account set money = money + 1000 where name = '李四';
So we need to consolidate the above code into a single transaction that executes completely before committing.
-- See how the transaction commits
SELECT @@AUTOCOMMIT;
-- Set the transaction commit method, 1 for auto-commit, 0 for manual commit, this setting is only valid for the current session
SET @@AUTOCOMMIT = 0;
-- commits the transaction
COMMIT;
-- roll back the transaction
ROLLBACK;
The second way
-- Open transaction.
START TRANSACTION or BEGIN TRANSACTION;
-- Commit the transaction.
COMMIT;
-- Rollback transaction.
ROLLBACK;
After adjusting the transaction, rerun sql
-- 1. Query Zhang San's account balance
select * from account where name = 'Zhang San';
-- 2. set Zhang San's account balance -1000
update account set money = money - 1000 where name = '张三';
-- 3. update the balance of Li Si's account +1000
update account set money = money + 1000 where name = '李四';
commit;
The Four Characteristics of Transactions
Four main characteristics ACID.
- Atomicity: transactions are indivisible minimal operations that either all succeed or all fail.
- Consistency: A transaction must complete with all data in a consistent state.
- Isolation: The isolation mechanism provided by the database system to ensure that transactions operate in an independent environment free from external concurrent operations.
- Durability: Once a transaction is committed or rolled back, its changes to the data in the database are permanent.
Concurrent Transaction Issues
| Problem | Description |
|---|---|
| Dirty Read | A transaction reads data that has not been committed by another transaction |
| Non-repeatable reads | A transaction reads the same row in succession, but reads different data twice. |
| Phantom reads | A transaction queries for data that does not exist, but when it inserts the data, it finds that the row already exists. |
Dirty Reads
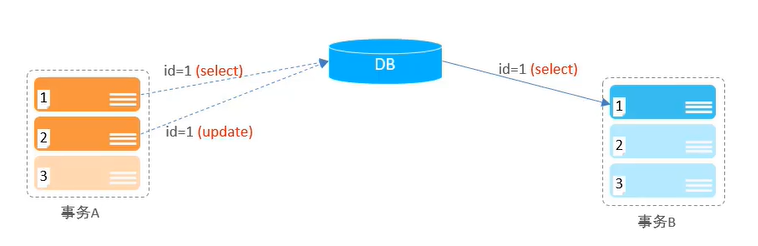
In the diagram below, Transaction A updates 1, but has not yet committed, and is then looked up by Transaction B. This leads to the possibility that Transaction A eventually decides not to commit, but Transaction B takes it seriously, so this phenomenon is called a dirty read.
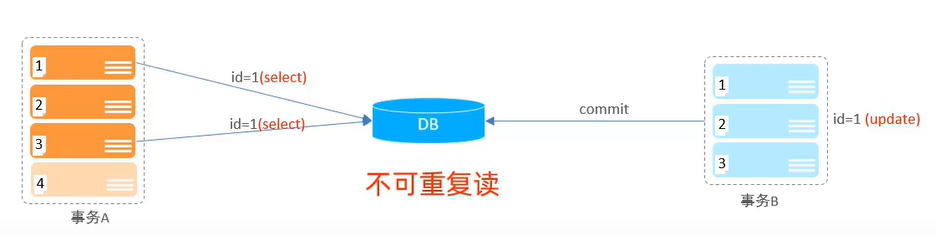
Non-repeatable reads
In the diagram below, Transaction A queries the first time, Transaction B updates the data, and Transaction A queries the second time and finds that the result is different from the first query.
Phantom reads
In the following diagram, Transaction A reads the data with id 1 as empty, Transaction B inserts the data with id 1, then Transaction A tries to insert this data and finds that it cannot (e.g. it is constrained by the primary key), then Transaction A re-queries it and still cannot find the data with id 1 (because we have solved the [non-repeatable], the result of the query is the same as the first query). (because we have solved [non-repeatable], the result is the same as the first query).

Transaction Isolation Levels
MySQL's default transaction isolation level is Repeatable Read
Oracle's default transaction isolation level is Read committed
| Isolation Level | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read (default) | × | × | |
| Serializable |
√ Read is the lowest performance; Read is the lowest performance.
Serializable has the lowest performance; Read uncommitted has the highest performance and the worst data security.
-- To view the transaction isolation level.
SELECT @@TRANSACTION_ISOLATION;
-- To set the transaction isolation level.
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE };
-- SESSION is the session level, indicating that it is only valid for the current session
-- GLOBAL means valid for all sessions